Overview
MUMIE is a Learning Management System (LMS) for Mathematics, developed and maintained by integral-learning GmbH. It can be used stand-alone or as an integral part of a course in a generic LMS like Moodle. The main objective is to support mathematical learning and teaching at the university level.
The system comes with a web-based authoring tool. The content is granular. It can be assembled into structures such as lectures, worksheets and courses to provide the learner with an integrated learning environment. The content is usually stored in the cloud
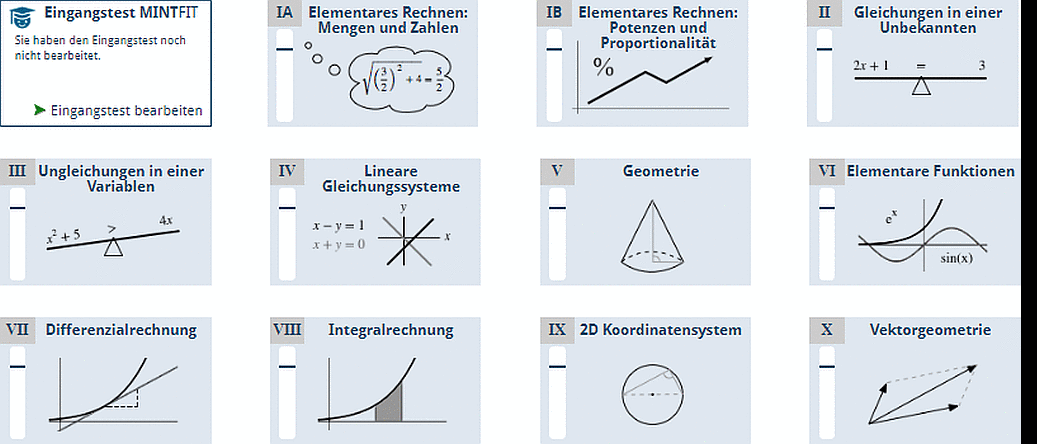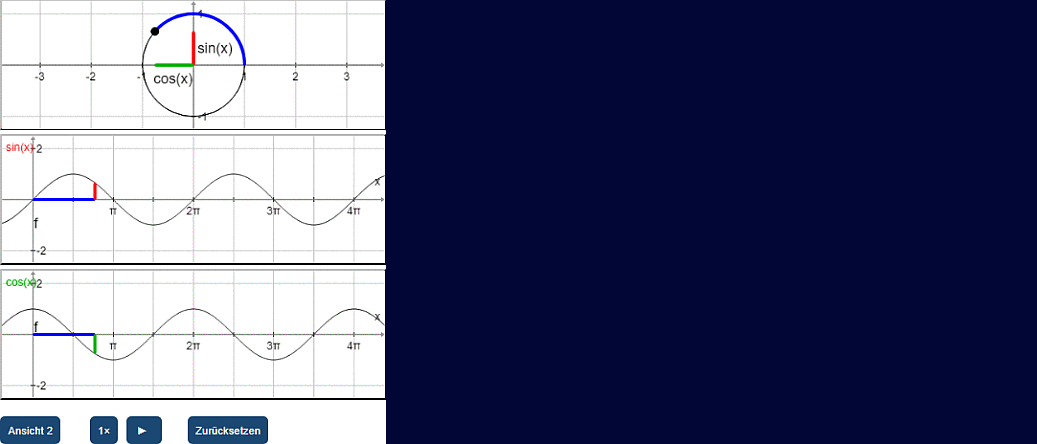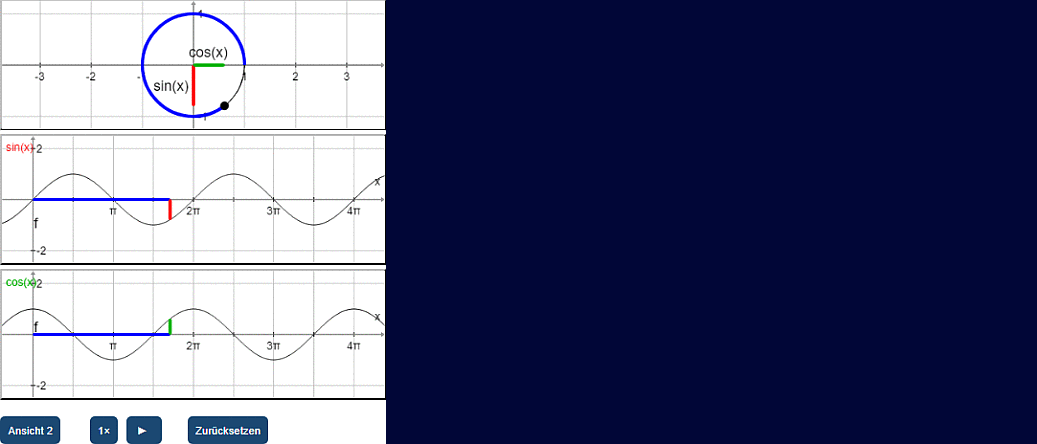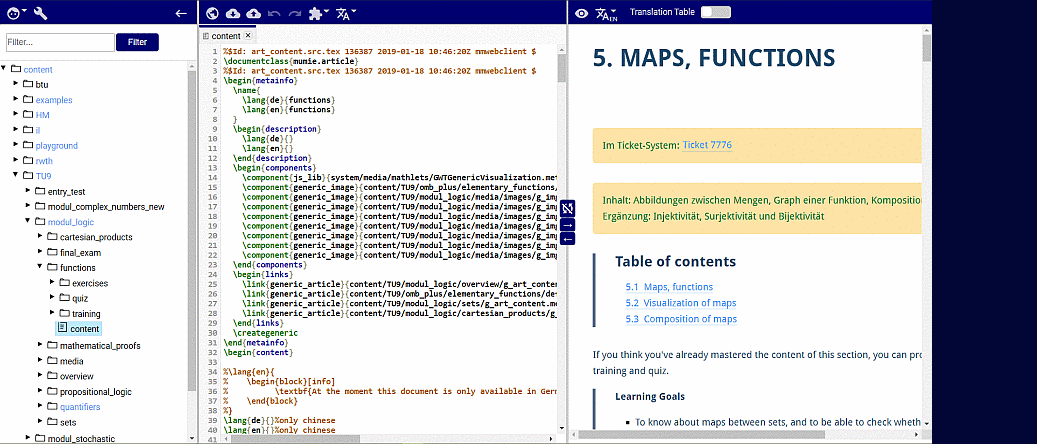
Here is a selection of features
- problems and quizzes accepting numbers and algebraic expressions with automatic correction and feedback
- training environments
- dynamic interactive visualization of functional expressions
- support of different languages
- text, audio and video content
- integrated chat
- integral representation of textbook, examples, problems
- scalable integration from individual elements to entire courses into existing LMSs eg Moodle
- simple to use web-based authoring tool for collaborative working, latex-based
For more details, visit our demo course on https://demo.mumie.net.